Joliciel Informatique. assaf@joli-ciel.com
CLLE-ERSS: CNRS & University of Toulouse. assaf.urieli@univ-tlse2.fr
The Talismane Suite
Introduction
Talismane is a statistical transition-based dependency parser for natural languages written in Java. It was developed within the framework of Assaf Urieli's doctoral thesis at the CLLE-ERSS laboratory in the Université de Toulouse, France, under the direction of Ludovic Tanguy. Many aspects of Talismane's behaviour can be tuned via the available configuration parameters. Furthermore, Talismane is based on an open, modular architecture, enabling a more advanced user to easily replace and/or extend the various modules, and, if required, to explore and modify the source code. It is distributed under an AGPL open-source license in order to encourage its non-commercial redistribution and adaptation.
Talismane stands for "Traitement Automatique des Langues par Inférence Statistique Moyennant l'Annotation de Nombreux Exemples" in French, or "Tool for the Analysis of Language, Inferring Statistical Models from the Annotation of Numerous Examples" in English.
Talismane should be considered as a framework which could potentially be adapted to any natural language. The present document presents a default implementation of Talismane for French, which uses the French Treebank as a training corpus, the Lefff as a lexicon, and a tagset, features and rules specific to French. This implementation is contained in the French language pack. Other language packs are available as well.
Talismane is a statistical toolset and makes heavy use of a probablistic classifier (currently either Linear SVM, Maximum Entropy or Perceptrons). Linguistic knowledge is incorporated into the system via the selection of features and rules specific to the language being processed.
The portability offered by Java enables Talismane to function on most operating systems, including Linux, Unix, MacOS and Windows.
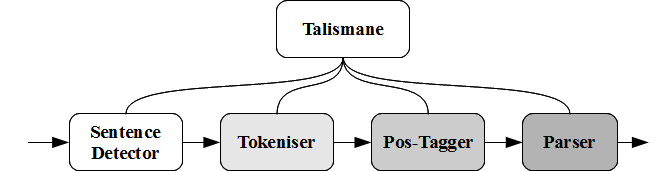
Talismane consists of four main modules which transform a raw unannotated text into a series of syntax dependency trees. It also contains a number of pre-processing and post-processing filters to manage and transform input and output. In sequence, these modules are:
- sentence detector
- tokeniser
- pos-tagger
- syntax parser
Each of the modules in the processing chain can be used independently if desired.
Sentence Detector
The Talismane Sentence Detector takes a stream of raw unannotated text as input, and breaks it up into sentences as output. It is based on a statistical approach, where each potential sentence boundary character is tested and marked as either a true or a false boundary.
In the default language pack for French, the Sentence Detector was trained using the French Treebank [Abeillé and Clément, 2003].
More details on Talismane Sentence Detector configuration and usage can be found here.
Tokeniser
A token is a single syntaxic unit. While the vast majority of tokens are simply words, there can be exceptions: for example, in English, the two words "of course" form a single token, while in French, the single word "au" is composed of two tokens, "à" and "le". The Talismane Tokeniser takes a sentence as input, and transforms it into a sequence of tokens as output. It combines a pattern-based approach with (optionally) a statistical approach. The patterns are language specific, and ensure that only areas where any doubt exists concerning the tokenisation are actually tested statistically.
The default French language pack thus comes with a list of patterns for French. The statistical model was trained using a modified version of the French Treebank [Abeillé and Clément, 2003]. This modified version includes specific tokenising decisions about each pattern-matching sequence in the treebank, which don't necessarily match the French Treebank's initial decision on what consists in a "compound word".
More details on Talismane Tokeniser configuration and usage can be found here.
Pos-Tagger
The Talismane Pos-Tagger takes a sequence of tokens (forming a sentence) as input, and adds a part-of-speech tag to each of these tokens as output, along with some additional sub-specified information (lemma, morpho-syntaxic details). It combines a statistical approach based on the use of a probabilistic classifier with a linguistic approach via the features used to train the classifier and the symbolic rules used to override the classifier.
In the default French language pack, the Pos-Tagger uses a tagset based on the one proposed by [Crabbé and Candito 2008] in their work on statistical dependency parsing for French, with some minor alterations. However, Talismane's architecture makes it fairly straightforward to replace this tagset with another tagset, as long as a statistical model is retrained for the new tagset.
After pos-tagging, the Pos-Tagger assigns lemmas and detailed morpho-syntaxic information. In the current version, this information is sub-specified, meaning it is only provided if it is found in the lexicon, in this case the Lefff [Sagot et al, 2006]. The Lefff can be replaced and/or extended by other lexical resources.
In the default French language pack, the Pos-Tagger was trained using the French Treebank [Abeillé and Clément, 2003].
More details on Talismane Pos-Tagger configuration and usage can be found here.
Syntax parser
The Talismane Syntax Parser is a transition-based statistical dependency parser, based on the work described by [Nivre, 2008], but modified in several significant ways.
It takes a sequence of pos-tagged tokens (with additional sub-specified lemmas and morpho-syntaxic information) as input, and generates a dependency tree as output, or a dependency forest if any nodes were left unconnected.
The default French Implmentation was trained using the French Treebank [Abeillé and Clément, 2003], automatically converted to a projective dependency treebank by [Candito et al., 2010A].
More details on Talismane Parser configuration and usage can be found here.
Licenses
The Talismane suite
Talismane is free software: you can redistribute it and/or modify it under the terms of the GNU Affero General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
Talismane is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License along with Talismane. If not, see this page.
The documentation
The present document is distributed udner the Creative Commons BY-NC 3.0 license. You are free to copy, distribute and transmit the work, and to adapt the work under the conditions that:
How to cite Talismane?
To cite Talismane, please use the following publication:
You may use the following bibtex:
@phdthesis{Urieli2013Talismane,
title={Robust French syntax analysis: reconciling statistical methods and linguistic knowledge in the Talismane toolkit},
author={Urieli, Assaf},
year={2013},
school={Universit{\'e} de Toulouse II le Mirail}
}
Typographic conventions
Various typographic conventions will be used in the present document.
user@computer:~$ command
Basic usage
Installation
java -version
From a precompiled executable
The simplest way to use Talismane is by downloading the pre-compiled executable in the GitHub releases section.
On the latest release, click on the talismane-X.X.Xb.zip asset to download it to your hard drive. Unzip the zip file. All command lines assume you have navigated to the folder where this file is unzipped.
You will probably also need a language pack for the language you wish to analyse. Currently available languages include English and French. For exmaple, if you wish to analyse French text, you will need the French language pack, which is in the frenchLanguagePack-X.X.Xb.zip asset on the releases page.
This language pack needs to remain zipped. Place it in the same directory where you unzipped Talismane (the one containing JAR files).
All examples in this manual assume you have navigated to the directory into which Talismane has been unzipped.
Now, navigate to the directory containing the Talismane JAR files and your language pack ZIP file.
java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse endModule=postag inFile=test.txt outFile=output.txt
From the sources using Git
The Talismane suite is available on the open-source project management platform GitHub. More advanced users with some knowledge of Java may wish to compile the source code directly from Git.
mkdir Talismane cd Talismane git clone https://github.com/urieli/talismane
ant -version
ant clean ant jar
cd dist ls
java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse endModule=postag inFile=test.txt outFile=output.txt
Quick start
This section helps you get up and running quickly with Talismane's default French language pack, which is contained in the file frenchLanguagePack-version.zip (where version in the shell commands below should be replaced by the version you downloaded).
Parsing a sentence
First, you will parse a French sentence.
Talismane can either work with input and/or output files, or directly from the shell using the standard streams STDIN and STDOUT.
echo "Les poules du couvent couvent." | java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse 1 Les les DET det n=p 2 det _ _ 2 poules poule NC nc g=f|n=p 5 suj _ _ 3 du de P+D P+D g=m|n=s 2 dep _ _ 4 couvent couvent NC nc g=m|n=s 3 obj _ _ 5 couvent couver V v n=p|p=3|t=pst 0 root _ _ 6 . . PONCT PONCT _ 5 ponct _ _
stdin and stdout
Whether or not Talismane uses stdin and stdout depends on the inclusion of the arguments inFile and outFile.
The following command takes a text file as entry, test.txt, and outputs the result into the current shell.
java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse inFile=test.txt
Conversely, the following command takes the value of echo command as input, processes it, and stores the result in output.txt.
echo "Les poules du couvent couvent." | java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse outFile=output.txt
This command has an identical result to the previous command, but uses stream redirection to write the output to the file output.txt:
echo "Les poules du couvent couvent." | java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse > output.txt
Finally, this command reads the sentences from one file, and writes the parsed result to another:
java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse inFile=test.txt outFile=output.txt
Integration with Unix Tools
By using the standard input and output streams, Talismane integrates well with the basic Unix tools, enabling the user to easily process the output data.
For example, the following command allows us to recuperate the 2nd column (the token) and the 4th column (the postag) from the parser's default output:
echo "Les poules du couvent couvent." | java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse | cut -f2,4 Les DET poules NC du P+D couvent NC couvent V . PONCT
While this command replaces DET by DETERMINANT.
echo "Les poules du couvent couvent." | java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse | perl -pe 's/DET/DETERMINANT/g
Finally, this command gives the total number of tokens and sentences processed:
echo "Les poules du couvent couvent." | java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse | perl -pe 'END{print "tokens:$i\nsentences:$p\n"} if (/^\r$/) {$p++} else {$i++}'
Arguments
Talismane requires several arguments in order to function correctly. If Talismane is called without any arguments, it will display a concise online help, simply listing the required argments.
Talismane provides several basic modes of operation:
In all operating modes, various additional arguments can be used to modify Talismane's behaviour. Details on these arguments are provided in the following sections.
Arguments shared by all modes
Arguments shared by analysis and process mode
Arguments used by analysis mode only
Arguments used by process mode only
Arguments used by evaluate, train, compare and process modes
Arguments shared by evaluate and compare modes
Arguments shared by analyse and evaluate modes
Will be ignored if set to 0.
If analysis jumps out because of free memory descends below this limit, there will be a parse-forest instead of a parse-tree, with several nodes left unattached. Default is 64k.
Arguments used by the compare mode only
Arguments used by the train mode only
There are many arguments used by the train mode only, including training algorithm parameters. These are described in more detail in the section on Training parameters.
Default configuration
Introduction
The default French language pack is setup with certain configuration options, and uses a set of default statistical models.
This section describes these default options and models, and explains which areas can be modified easily, and which require more advanced usage.
Statisical models, features and rules
In order to provide an off-the-shelf solution, each module in the Talismane suite comes with a statistical model specifically trained for the task in question (sentence detection, tokenising, pos-tagging, parsing). Terminologicially, these models were built using machine learning techniques for automatic statistical classification. Thus, each of the tasks listed above has been transformed into a classification task. The case of pos-tagging is the most emblamatic: we take a given word in a sentence as input, and classify it by assigning a single part-of-speech out of a closed set.
In practice, we begin with a training corpus, which is a large body of text which has been manually annotated for the phenomenon that we wish to annotate automatically. Then, a statistical model is trained by projecting various features onto the training corpus, in an attempt to recognise patterns within the language. When asked to annotate a new text, the machine first projects the same set of features onto the new text, then feeds the feature results into the statistical model, and finally selects a classification which is statistically the most likely, in view of the patterns seen in the training corpus. The actual nature of features is described in this section.
Now, for certain tasks, Talismane also allows the user to override the decision taken by the statistical model, using pre-configured rules. Rules are particularly useful for encoding phenomena which are statistically rare or absent from the training corpus, but about which the linguist is quite sure. They can also be used to hard-code decisions to be taken in a specialised corpus (e.g. named entities). Thus, features are used in statistical model training, while rules are only used when actually analysing a text.
Features
In automatic classification, the machine tries to correctly classify a given linguistic context. The linguistic context to classify depends on the task: in the case of pos-tagging, for example, the linguistic context is a single word (or more precisely, a single token) within a sentence. A feature is an attribute of the linguistic context, which can provide information about the correct classification for this context. For example, when building a French pos-tagger, we can create a feature called *ait which returns true if a word ends with the suffix "-ait" and false otherwise. It can be seen that many words for which the *ait feature returns true (e.g. "parlait") should be classified as verbs in the imperfect tense.
In Talismane, a feature can return a boolean value (i.e. true or false), a numeric value (integer or decimal), or a string. There is a standard feature definition syntax which is identical for all modules. A simple example for the pos-tagger is the feature FirstWordInSentence(), which returns true if the word in question is the first one in the sentence, and false otherwise.
Feature selection is the manner in which the linguist brings his linguistic knowledge to bear on Talismane's statistical models. The list of features used by the default French language pack can be found in the Git directory talismane_trainer_fr/features.
Rules
Rules are applied when Talismane analyses new data, allowing the system to bypass the statistical model and automatically assign a certain classification to a certain phenomenon. Any boolean feature can be transformed into a rule: if the boolean feature returns true for a given context, the rule is applied, and the statistical model is skipped.
Rules thus add a symbolic dimension to the statistical approach. This makes it possible for Talismane to adapt to certain specific cases which are either under-represented or not represented at all in the training corpus. Rules, however, should be used with caution, as a large number of rules can make maintenance difficult.
Information on how to define the rules used for analysis can be found below.
Resources
Lefff
The default French language pack uses the Lefff (see [Sagot et al. 2006]) as its main lexical resource. More information about the Lefff can be found at http://www.labri.fr/perso/clement/lefff/. Every time Talismane is started, it loads the entire Lefff into memory, which typically takes at least 20 seconds (depending on system specs of course). This slows down performance for short text analysis, but speeds it up for longer text analysis. Note that Talismane is designed to enable the user to replace or extend the lexical resource by any other lexical resource implementing the required com.joliciel.talismane.posTagger.PosTaggerLexiconService interface. The Lefff lexicon, which is incorporated in electronic format in the default French language pack for Talismane, is distributed under the LGPLLR license.
In practice, the Lefff is used to project features onto the corpus, either as training features or as rules. For example, it can be used to create a feature checking if a certain word is listed in the Lefff as a verb, thus increasing the probability that the word is actually a verb. It can also be used in negative rules, excluding words from a closed-class parts-of-speech unless they are explicitly listed as belonging to that part-of-speech. The following negative rule, for example, does not allow Talismane to classify a word as a subordinating conjunction unless it is listed in the Lefff as a subordinating conjunction:
!CS Not(LexiconPosTag("CS"))
French TreeBank
The French Treebank is a syntaxically and morphologically annoted corpus (see [Abeillé and Clément, 2003]). It is annotated for syntaxic constituents (rather than dependencies), and includes some functional data about the relationship between these constituents. It is used indirectly by Talismane, as the training corpus on which its default statistical models are built for sentence detection, tokenising, and pos-tagging. The default parser model is trained on a version of the French Treebank converted to dependencies by [Candito et al. 2010].
Unlike the Lefff lexicon, the French Treebank is not distributed under a license which permits its redistribution with Talismane. Anybody wishing to construct new statistical models must either find another annotated corpus for French, or contact Anne Abeillé to request a copy of the French Treebank.
The tagset
The tagset used in the default French language pack is based on [Crabbé and Candito, 2008], with slight modification. The tags used are listed below.
| Tag | Part of speech |
|---|---|
| ADJ | Adjective |
| ADV | Adverb |
| ADVWH | Interrogative adverb |
| CC | Coordinating conjunction |
| CLO | Clitic (object) |
| CLR | Clitic (reflexive) |
| CLS | Clitic (subject) |
| CS | Subordinating conjunction |
| DET | Determinent |
| DETWH | Interrogative determinent |
| ET | Foreign word |
| I | Interjection |
| NC | Common noun |
| NPP | Proper noun |
| P | Preposition |
| P+D | Preposition and determinant combined (e.g. "du") |
| P+PRO | Preposition and pronoun combined (e.g. "duquel") |
| PONCT | Punctuation |
| PRO | Pronoun |
| PROREL | Relative pronoun |
| PROWH | Interrogative pronoun |
| V | Indicative verb |
| VIMP | Imperative verb |
| VINF | Infinitive verb |
| VPP | Past participle |
| VPR | Present participle |
| VS | Subjunctive verb |
In Talismane, the tagset is contained in the file talismane_trainer_fr/postags/CrabbeCanditoTagset.txt. The many-to-many mapping between the morpho-syntaxic categories used by the French Treebank and this tagset is found in the file talismane_trainer_fr/postags/ftbCrabbeCanditoTagsetMap.txt. The many-to-many mapping between the morpho-syntaxic categories used by the Lefff and this tagset are found in the file lefff/resources/lefffCrabbeCanditoTagsetMap.txt.
Output format
Talismane's default output format for parsing is based on the CoNLL format. This format was defined for the CoNLL evaluation campaign for multilingual morpho-syntaxic annotation. The elements are separated into columns by tab characters. Other formats may be defined in templates, as described in the advanced usage section.
The CoNLL format used by Talismane outputs the following information in each row:
For example:
6 couvent couver V v n=s|p=3|t=pst 0 root _ _
The additional morpho-syntaxic information includes:
Advanced usage
Talismane comes with a default French language pack. It is possible to modify the behaviour of this language pack in three ways (ordered by increasing complexity):
The present section concentrates on the configuration files, though some information in this section (e.g. feature syntax) has a direct bearing on training new statistical models. There is a short section in the end explaining how to train new models.
Modifying the output format
In order to define the output format, Talismane defines an output "object" for each module, and processes this object using a Freemarker template. More information on writing these templates can be found in the Freemarker's Template Author's Guide. The default French language pack comes with a default template for each module. These default templates can be found in the source code of the talismane_core project, in the package com.joliciel.talismane.output.
By using the template argument in talismane-fr-version.jar, the user can override the default template with a template of his choice.
The following is a schematic view of the output interface for the parser:
| class | class description | field | field description |
|---|---|---|---|
| sentence | a top-level object, which is simply a sequence of syntaxic units, see unit below | ||
| configuration | a top-level object giving more parsing details, see com.joliciel.talismane.parser.ParseConfiguration for details | ||
| unit | a single syntaxic unit, i.e. a pos-tagged token with a dependency | token | the actual token (see below) |
| tag | it's pos-tag | ||
| lexicalEntry | the lexical entry found for this token/pos-tag combination | ||
| governor | the token's governor (another unit) | ||
| label | the dependency label between the governor and the token | ||
| lemmaForCoNLL | the "best" lemma for this pos-tagged token, formatted for CoNLL (spaces and blanks replaced by underscores) | ||
| token | a single token | text | the token that was processed by Talismane |
| originalText | the original token that was in the raw text | ||
| textForCoNLL | the original text with spaces replaced by underscores, and an empty entry replaced by an underscore | ||
| index | the token's placement in this sentence (starting at 1) | ||
| fileName | the file name in which the token was found | ||
| lineNumber | the line number within the file (starting at 1) | ||
| columnNumber | the column number within the line (starting at 1) | ||
| precedingRawOutput | any text in the original file that has been marked for raw output just before this token | ||
| lexical entry | a lexical entry from the lexicon | word | the lexical form of this entry |
| lemma | the lemma for this entry | ||
| category | the main grammatical category for this entry | ||
| morphology | additional morpho-syntaxic details for this entry | ||
| morphologyForCoNLL | additional morpho-syntaxic details for this entry, in CoNLL format (separated by a vertical pipe) | ||
Thus, the default parser output uses the following Freemarker template to produce the CoNLL output:
[#ftl]
[#list sentence as unit]
[#if unit.token.precedingRawOutput??]
${unit.token.precedingRawOutput}
[/#if]
[#if unit.token.index>0]
${unit.token.index?c} ${unit.token.textForCoNLL} ${unit.posTaggedToken.lemmaForCoNLL} ${unit.tag.code} ${(unit.lexicalEntry.category)!"_"} ${(unit.lexicalEntry.morphologyForCoNLL)!"_"} ${(unit.governor.token.index?c)!"0"} ${unit.label!"_"} _ _
[/#if]
[/#list]
If we wanted to add on the original location, we could add the following:
${unit.token.fileName} ${(unit.token.lineNumber)?c} ${(unit.token.columnNumber)?c}
Similarly, the following is a schematic view of the output interface for the pos-tagger:
| class | class description | field | field description |
|---|---|---|---|
| sentence | a top-level object, which is simply a sequence pos-tagged units, see unit below | ||
| unit | a single pos-tagged token | token | the actual token (see below) |
| tag | it's pos-tag | ||
| lexicalEntry | the lexical entry found for this token/pos-tag combination | ||
| token | a single token | text | the token that was processed by Talismane |
| originalText | the original token that was in the raw text | ||
| textForCoNLL | the original text with spaces replaced by underscores, and an empty entry replaced by an underscore | ||
| index | the token's placement in this sentence (starting at 0) | ||
| fileName | the file name in which the token was found | ||
| lineNumber | the line number within the file (starting at 1) | ||
| columnNumber | the column number within the line (starting at 1) | ||
| precedingRawOutput | any text in the original file that has been marked for raw output just before this token | ||
| lexical entry | a lexical entry from the lexicon | word | the lexical form of this entry |
| lemma | the lemma for this entry | ||
| category | the main grammatical category for this entry | ||
| morphology | additional morpho-syntaxic details for this entry | ||
| morphologyForCoNLL | additional morpho-syntaxic details for this entry, in CoNLL format (separated by a vertical pipe) | ||
The default Freemarker template for the pos-tagger is:
[#ftl]
[#list sentence as unit]
[#if unit.token.precedingRawOutput??]
${unit.token.precedingRawOutput}
[/#if]
${unit.token.index?c} ${unit.token.textForCoNLL} ${unit.lemmaForCoNLL} ${unit.tag.code} ${(unit.lexicalEntry.category)!"_"} ${(unit.lexicalEntry.morphologyForCoNLL)!"_"}
[/#list]
This template would produce the following output:
0 Les les DET det n=p 1 poules poule NC nc g=f|n=p 2 du de P+D P+D g=m|n=s 3 couvent couvent NC nc g=m|n=s 4 couvent couver V v n=p|p=3|t=pst 5 . . PONCT PONCT _
Modifying the input format
You may sometimes need to apply Talismane to text that has already been processed elsewhere - either broken up into sentences, or tokenised, or pos-tagged. In this case, you would set the startModule argument to tokeniser, postag or parse, indicating that sentence boundary detection is not the first required task. Thus, Talismane is no longer being used to analyse raw text, but rather annotated text, and has to be told how to identify the annotations.
Each startModule has its own default format.
Input format for the tokeniser
The tokeniser will always assume there is one sentence per line.
Input format for the pos-tagger
The pos-tagger will always assume there is one token per line, and and empty line between sentences. It thus needs to find a token in each line of input. The default input format, .+\\t(.+) assumes an index, a tab and a token on each line, e.g.
1 Je
To override this format, use the inputPattern or inputPatternFile arguments to indicate a new regex. The regex must contain a single group in parentheses, indicating the location of the token, and is a regular Java regular expression pattern in all other respects.
Input format for the parser
The parser assumes one pos-tagged token per line, and an empty line between sentences. It thus needs to find a token and a pos-tag in each line of input. The default input format, .*\t%TOKEN%\t.*\t%POSTAG%\t.*\t.*\t, corresponds to Talimane's default output format for the pos-tagger.
This pattern indicates that the %TOKEN% will be found after the first tab, and the %POSTAG% after the third tab. To override this format, use the inputPattern or inputPatternFile arguments to indicate a new regex. The regex must contain the strings %TOKEN% and %POSTAG% to indicate the positions of the token and pos-tag respectively, and is a regular Java regular expression pattern in all other respects.
Input formats for evaluation
When evaluating the pos-tagger, the input format needs to indicate the expected pos-tag for each token. It is thus identical to the input format for the parser above.
When evaluating the parser, the input format must indicate the %INDEX%, %TOKEN%, %POSTAG%, %LABEL% and %GOVERNOR%, as follows:
The default format corresponds to the CONLL format: %INDEX%\t%TOKEN%\t.*\t%POSTAG%\t.*\t.*\t%GOVERNOR%\t%LABEL%\t_\t_, with the assumption that the pos-tag which interests us is the "coarse" CoNLL pos-tag (rather than the fine-grained one).
Filtering the input: text marker filters
Many input texts have sections that need to be parsed and other sections that should be skipped or replaced. For example, in XML, it may only be necessary to parse text contained between certain tags, and to skip certain tags inside that text.
The simplest way to do this is by applying regular expression filters to the raw text, using the textFilters argument. The indicated text marker filters will either precede the default filters for a given language, or replace them. In the latter case, the file path should be preceded with the string "replace:".
The textFilters file has the following tab-delimited format per line:
FilterType Markers Regex GroupNumber* Replacement
The meaning of these fields is given below:
Below is a table of allowable markers. Markers are either stack based or unary. Stack-based markers mark both the beginning and end of section of text, and can be nested. Unary markers apply a single action at a given point in the text: if unary markers (e.g. start and end markers) are placed inside an area marked by a stack-based marker, their action will only affect this area. For maximum robustness, the best strategy is to reserve stack-based markers for very short segments, and use unary markers instead of excessive nesting.
| Marker type | Description |
|---|---|
| SKIP | Skip any text matching this filter (stack-based). |
| INCLUDE | Include any text matching this filter (stack-based). |
| OUTPUT | Skip any text matching this filter, and output its raw content in any output file produced by Talismane (stack-based). |
| SENTENCE_BREAK | Insert a sentence break. |
| SPACE | Replace the text with a space (unless the previous segment ends with a space already). Only applies if the current text is marked for processing. |
| REPLACE | Replace the text with another text. Should only be used for encoding replacements which don't change meaning - e.g. replace "é" by "é". Only applies if the current text is marked for processing. |
| STOP | Mark the beginning of a section to be skipped (without an explicit end). Note that the processing will stop at the beginning of the match. If this marker is placed inside an area marked by SKIP, INCLUDE or OUTPUT, it will only take effect within this area. It can be reversed by a START marker. |
| START | Mark the beginning of a section to be processed (without an explicit end). Note that the processing will begin AFTER the end of the match. If this marker is placed inside an area marked by SKIP, INCLUDE or OUTPUT, it will only take effect within this area. It can be reversed by a START marker. |
| OUTPUT_START | Mark the beginning of a section to be outputted (without an explicit end). Will only actually output if processing is stopped. Stopping needs to be marked separately (via a STOP marker). Note that the output will begin at the beginning of the match. If this marker is placed inside an area marked by OUTPUT, it will only take effect within this area. It can be reversed by a OUTPUT_STOP marker. |
| OUTPUT_STOP | Mark the end of a section to be outputted (without an explicit beginning). Starting the processing needs to be marked separately. Note that the output will stop at the end of the match. If this marker is placed inside an area marked by OUTPUT, it will only take effect within this area. It can be reversed by a OUTPUT_START marker. |
The text marked for raw output will only be included if the output template explicitly includes it using the precedingRawOutput field (as is the case for the default templates). More information can be found in the output template section.
Text marker filter examples
RegexMarkerFilter SKIP <skip>.*</skip>
RegexMarkerFilter SKIP <b> RegexMarkerFilter SKIP </b>
RegexMarkerFilter SKIP \n(Figure \d+:) 1
RegexMarkerFilter INCLUDE <text>(.*)</text> 1
RegexMarkerFilter OUTPUT <marker>.*</marker>
RegexMarkerFilter OUTPUT <marker>(.*)</marker> 1
RegexMarkerFilter SKIP,SENTENCE_BREAK (\r\n|[\r\n]){2} 0
RegexMarkerFilter SPACE [^-\r\n](\r\n|[\r\n]) 1
RegexMarkerFilter REPLACE é é
RegexMarkerFilter START <text>
RegexMarkerFilter STOP </text>
RegexMarkerFilter STOP,OUTPUT_START <marker>
RegexMarkerFilter START,OUTPUT_STOP </marker>
Token filters
Unlike text filters, token filters are used to mark certain portions of the text as "indissociable", and optionally to replace them with a replacement text when performing analysis. These portions will never be broken up into several different tokens. The tokeniser may still join them with other atomic tokens to create larger tokens containing them.
For example, the user may wish to indicate that e-mail addresses are indissociable, and to replace them by the word "EmailAddress" for analysis. He may then wish to indicate that EmailAddress should always be treated as a proper noun, using a pos-tagger rule.
Token filters are provided to Talismane in a configuration file using the tokenFilters command-line parameter. The indicated token filters will either precede the default filters for a given language, or replace them. In the latter case, the file path should be preceded with the string "replace:". Lines beginning with a # will be skipped. Other lines will have the following format:
FilterType Regex Replacement*
The meaning of these fields is given below:
For example, the following filter would replace all e-mail addresses by the word EmailAddress:
TokenRegexFilter \b([\w.%-]+@[-.\w]+\.[A-Za-z]{2,4})\b EmailAddress
As mentioned above, token filters can include a list of arguments. These are comma-delimited inside parentheses. The following arguments are predefined:
Additional arguments are arbitrary and application specific values. For example:
TokenRegexFilter(group=2,featureType=name,language=en) \b(\p{WordList(FrenchNames,true)}) +([A-Z]\p{Alpha}+)\b
In the above case, we indicate that the token defined by group 2 of the expression should be given the attributes featureType=name and language=en. These attributes are meaningless to Talismane: but they can be read from Token.getAttributes() for downstream applications.
Note in the above example the \p{WordList(FrenchNames,true)} in the regular expression. Token filters can include a word list in a regular expression, which is read from a newline-delimited file. The word list must be included in the external resources directory. Regarding this file, the first line must be "Type: WordList", otherwise an exception gets thrown. The default name will be the filename. If a line starts with the string "Name: ", the default name will be replaced by this name. All lines starting with # are skipped. All other lines contain words.
The \p{WordList(name,diacriticsOptional*,uppercaseOptional*)} command transforms this file into part of a regex. This will be a pipe-delimited list of words. Take a list containing "Chloé", "Marcel", "Joëlle" and "Édouard". By default, this will be transformed into Chloé|Marcel|Joëlle|Édouard. If diacriticsOptional=true, diacritics will not be required, and we get Chlo[ée]|Marcel|Jo[ëe]lle|[ÉE]douard. If uppercaseOptional=true, upper-case characters are not required, and we get [Cc]hloé|[Mm]arcel|[Jj]oëlle|[Éé]douard. If both are true, we get [Cc]hlo[ée]|[Mm]arcel|[Jj]o[ëe]lle|[ÉéEe]douard.
Token sequence filters
Token sequence filters are applied to a token sequence as a whole, after tokenisation and before pos-tagging. The most common usage is to modify the token text in order to normalise it in some way. Talismane includes various pre-defined filters:
The following additional filters are available for French:
Modifying the rules
As stated previously, while features are applied during statistical model training, rules are applied during text analysis in order to bypass the statistical model. As such, rules are independent of the statistical model, and can be configured differently for each analysis. Rules are simply boolean features associated with either a positive classification (i.e. you must assign this classification if the features returns true) or a negative classification (i.e. you cannot assign this classification if the feature returns true).
Pos-tagger rules
Pos-tagger rules are configured using the posTaggerRules argument, which points at a file containing the rules. If the rules are meant to replace the default rules for a given language, the file path in the option should be preceded by the string "replace:". Otherwise, they will be applied prior to the default rules. The file format is as follows:
[postag|!postag]\t[boolean feature]
Where \t is that tab character. A ! before the postag implies a negative rule (or constraint). The boolean feature syntax is described in greater detail in the Feature definition syntax section below. The rules used by the default French language pack can be found in the talismane_fr project, at src/com/joliciel/talismane/fr/resources/posTaggerConstraints_fr.txt.
Negative rules, or constraints, are typically used around closed classes. The following constraint, for example, does not allow the pos-tagger to classify a word as a subordinating conjunction if it isn't listed in the lexicon as a subordinating conjunction:
!CS Not(LexiconPosTag("CS"))
Alternatively, the following constraint ensures that a word which is listed only under closed classes in the lexicon (such as "le" in French) should never be classified as a common noun:
!NC HasClosedClassesOnly()
Positive rules are typically used for very specific cases that are under-represented in the training corpus, but which the linguist feels should always result in a certain classification. For example, the positive rule below tells Talsimane to classify as an adjective any word representing a cardinal, when preceded by a determinent and followed by a token which, according to the lexicon, can be classified as a noun:
ADJ PosTag(History(-1))=="DET" & Word("deux","trois","quatre","cinq","six","sept","huit","neuf","dix") & LexiconPosTag(Offset(1),"NC")
Parser rules
Parser rules are configured using the parserRules argument, which points at a file containing the rules. If the rules are meant to replace the default rules for a given language, the file path in the option should be preceded by the string "replace:". Otherwise, they will be applied prior to the default rules. The file format is as follows:
[transitionCode|!transitionCode]\t[boolean feature]
Where \t is the tab character. A ! before the transition code implies a negative rule (or constraint). The boolean feature syntax is described in greater detail in the Feature definition syntax section below. Note that negative rules can indicate multiple transition codes in the same rule, by separating the transition codes with semicolons.
Positive parser rules should be used with extreme caution, as they may easily degrade parser performance or even force the parser to abandon parsing mid-way.
For example, a user may wish to automatically attach a punctuation mark to its first potential governor, so as to avoid cluttering the beam with useless punctuation attachment options.
A first attempt might be:
RightArc[ponct] PosTag(Buffer[0])=="PONCT" LeftArc[ponct] PosTag(Stack[0])=="PONCT"
However, there are two issues here: first of all, a comma can have two labels: "coord" when it's a coordinant, and "ponct" otherwise. Secondly, after performing a RightArc we need to reduce the stack, so as to allow for further parsing. So, a better implementation would be:
RightArc[ponct] PosTag(Buffer[0])=="PONCT" & Not(LexicalForm(Buffer[0])==",") Reduce DependencyLabel(Stack[0])=="ponct" & Not(LexicalForm(Stack[0])==",") # If after all that we still don't have a dependent, we apply a LeftArc on the punctuation (should only occur with punct at start of sentence). LeftArc[ponct] PosTag(Stack[0])=="PONCT" & Not(LexicalForm(Stack[0])==",")
However, evaluation shows that while these rules radically speed up parsing at higher beams (about 50%), they also reduce accuracy, since the order of attachment in a shift-reduce algorithm determines the order in which other elements are compared, and attaching punctuation early makes it more likely to attach elements accross this punctuation mark.
Negative rules are far less risky, as they simply constrain choices. For example, you may wish to indicate that a verb should only have one subject, as follows:
!LeftArc[suj] PosTag(Buffer[0])=="V" & DependentCountIf(Buffer[0],DependecyLabel=="suj")>0
However, even this should be done with caution, as some configurations may justify two subjects (without coordination), as in French questions, when a pronoun clitic is repeated after the verb: "Mon copain est-il arrivé ?"
Feature definition syntax
Talismane uses a standard feature definition syntax for all modules, although each module supports specific functions for use within this syntax.
This syntax allows for the use of certain operators and parentheses for grouping, as well as certain generic functions. The operators are listed in the table below:
| Operator | Result | Description |
|---|---|---|
| + | integer/decimal | integer or decimal addition |
| - | integer/decimal | integer or decimal substraction |
| * | integer/decimal | integer or decimal multiplication |
| / | integer/decimal | integer or decimal division |
| % | integer | integer modulus |
| == | boolean | integer, decimal, string or boolean equality |
| != | boolean | integer, decimal, string or boolean inequality |
| < | boolean | integer or decimal less than operator |
| > | boolean | integer or decimal greater than operator |
| <= | boolean | integer or decimal less than or equal to |
| >= | boolean | integer or decimal greater than or equal to |
| & | boolean | boolean AND |
| | | boolean | boolean OR |
| (...) | n/a | grouping parenthesis |
| [...] | n/a | grouping brackets |
| "..." | string | encloses a string - double quotes can be escaped via \" |
The following are the generic functions supported by Talismane for all modules:
| Function | Type | Description |
|---|---|---|
| And(boolean,boolean,...) | boolean | Performs a boolean AND of any number of boolean features |
| Concat(string,string,...) | string | Merges two or more string features by concatenating their results and adding a | in between. Includes the string "null" if any of the results is null. |
| ConcatNoNulls(string,string,...) | string | Merges two or more string features by concatenating their results and adding a | in between. If any of the results is null, returns a null. |
| Graduate(decimal feature, integer n) | decimal | Takes a feature with a value from 0 to 1, and converts it to a graduated value of 0, 1/n, 2/n, 3/n, ..., 1. |
| ExternalResource(string name, string keyElement1, string keyElement2...) | string | Returns the class indicated in the named external resource for the set of key elements. See External Resources below. |
| MultivaluedExternalResource(string name, string keyElement1, string keyElement2...) | string collection | Returns the collection of classes/weights indicated in the named external resource for the set of key elements. See External Resources below. |
| IfThenElse(boolean condition, any thenResult, any elseResult) | any | Standard if condition==true then return one result else return another result. The results must both be of the same type. |
| IndexRange(integer from, integer to) | integer | Creates n separate features, one per index in the range going from "from" to "to".
Note: unlike other functions, index range can ONLY take actual numbers (e.g. 1, 2, 3) as parameters - you cannot pass it an integer function as a parameter. |
| Inverse(decimal) | decimal | Inverts a normalised double feature (whose values go from 0 to 1), giving 1-result. If the result is < 0, returns 0. |
| IsNull(any) | boolean | Returns true if a feature returns null, false otherwise. |
| Normalise(decimal feature, decimal minValue, decimal maxValue) | decimal | Changes a numeric feature to a value from 0 to 1, where any value <= minValue is set to 0, and any value >= maxValue is set to 1, and all other values are set to a proportional value between 0 and 1. |
| Normalise(decimal feature, decimal maxValue) | decimal | Like Normalise(decimal, decimal, decimal) above, but minValue is defaulted to 0. |
| Not(boolean) | boolean | Performs a boolean NOT of a boolean feature |
| NullIf(boolean condition, any feature) | any | If the condition returns true, return null, else return the result of the feature provided. |
| NullToFalse(boolean) | boolean | If the wrapped boolean feature returns null, will convert it to a false. |
| OnlyTrue(boolean) | boolean | If the boolean feature returns false, will convert it to a null. Useful to keep the feature sparse, so that only true values return a result. |
| Or(boolean,boolean,...) | boolean | Performs a boolean OR of any number of boolean features |
| Round(decimal) | integer | Rounds a double to the nearest integer. |
| ToString(any) | string | Converts a non-string feature to a string feature. If the feature result is null, will return the string "null". |
| ToStringNoNulls(any) | string | Converts a non-string feature to a string feature. If the feature result is null, will return null (rather than the string "null"). |
| Truncate(decimal) | integer | Truncates a double down to an integer. |
The specific functions that can be used with each of the Talismane modules are listed in the section concerning this module, below.
A very few features have "OnlyTrue" behaviour by default, and if the opposite behaviour is desired, the user needs to use NullToFalse. This is notably the example for the tokeniser feature Word().
Named features
Features in Talismane can be named, which allows them to be re-used by other features, and also simplifies the interpretation of any output files referring to features, as the name will be used instead of the full feature. This is done by giving the features a unique name, followed by a tab, followed by the feature itself, e.g.
IsMonthName Word("janvier","février","mars","avril","mai","juin","juillet","août","septembre","octobre","novembre","décembre")
IsDayOfMonth Word("31") & AndRange(NullToFalse(Word("31","au",",","et","à")), 1, ForwardLookup(IsMonthName()))
Note that IsMonthName is used by the IsDayOfMonth feature.
Parametrised features
It is also possible to pass parameters to named features, thus creating a "template" of sorts. Note that the parametrised features aren't analysed in and of themselves - they are only used as components for other features. To create a parametrised feature, add parentheses after the feature name containing a comma-separated list of parameter names, and re-use these parameters in the feature description, as follows:
IfThenElseNull(X,Y) NullIf(Not(X),Y) IsVerb(X) PosTag(X)=="V" | PosTag(X)=="VS" | PosTag(X)=="VIMP" | PosTag(X)=="VPP" | PosTag(X)=="VINF" | PosTag(X)=="VPR" VerbPosTag IfThenElseNull(IsVerb(Stack[0]),PosTag(Stack[0]))
Note that the VerbPosTag feature uses the feature templates IfThenElseNull and IsVerb.
A special case is the parametrised feature with zero parameters, generated by adding empty parentheses after the feature name: StackIsVerb(). This simply indicates to Talismane that the feature should not be computed on its own as a separate feature, but only when called by other features.
Feature groups
Features may be grouped together, by adding an additional feature group name separated by tabs from the feature name and the feature code, e.g.
LemmaStack0() PairGroup Lemma(Stack[0]) LemmaBuffer0() PairGroup LemmaOrWord(Buffer[0]) LemmaBuffer1() PairGroup LemmaOrWord(Buffer[1])
This allows us to construct additional features for an entire group (e.g. when we want to concatenate additional information for an entire group), as follows:
PairGroup_P ConcatNoNulls(PosTagPair(), PairGroup()) PairGroup_L ConcatNoNulls(LexicalisedPair(), PairGroup()) PairGroup_V ConcatNoNulls(LexicalisedVerbPair(), PairGroup())
String Collection features
String collection features are a special kind of feature, which evaluates to a collection of weighted strings at runtime (instead of evaluating to a single result).
They can be used anywhere a regular StringFeature is expected
However, in order to avoid a cross-product of all instances of the collection feature, each collection feature is evaluated up-front, and a single value is inserted at a time.
For example, take the String collection feature LexiconPosTags (returning each postag found in the lexicon for the current token). Imagine a crazy feature which returns the lexicon postags for the current token, but replaces the postag "V" with the word "Verb". It might look something like: IfThenElse(LexiconPosTags=="V","Verb",LexiconPosTags). If each instance of LexiconPosTags were evaluated separately, and the current token has 3 postags in the lexicon ("DET","P","CLO"), this feature would return a cross-product of the 2 calls (or 9 results) instead of the expected 3 results. Instead, Talismane evaluates LexiconPosTags up front, and then runs the feature 3 times, once for each result in the collection, filling in the result in the appropriate place as follows: IfThenElse("DET"=="V","Verb","DET"), IfThenElse("P"=="V","Verb","P"), IfThenElse("CLO"=="V","Verb","CLO").
In this document, these are indicated by with a return type of string collection.
If the top-level feature returns a boolean or an integer, it will be converted to a string, and concatenated to current the string collection result.
If the top-level feature returns a double, the string collection result will be returned, and its weight will be multiplied by the double result to give the final result.
If the top-level feature returns a string, the string collection result is not concatenated to the top-level feature result. It is assumed that the string already includes the string-collection result. If the user needs to include the string-collection result, it needs to be concatenated manually (typically via ConcatNoNulls).
See example feature files below fore details (e.g. Tokeniser feature file, which concatenates the TokeniserPatterns feature to the results).
Talismane modules
The Sentence Detector
The Talismane Sentence Detector examines each possible sentence boundary, and takes a binary decision on whether or not it is a true sentence boundary. Any of the following characters will be considered as a possible sentence boundary:
. ? ! " ) ] } » — ― ”
The sentence detector features also look at the atomic tokens surrounding this possible boundary - see tokeniser below for more details.
The following feature functions are available for the sentence detector:
| Function | Type | Description |
|---|---|---|
| BoundaryString() | string | Returns the actual text of the possible sentence boundary being considered. |
| Initials() | boolean | Returns true if the current token is "." and the previous token is a capital letter, false otherwise.. |
| InParentheses() | string | Returns "YES" if the current sentence break is between a "(" and ")" character without any intervening characters ".", "?" or "!".
Returns "OPEN" if a parenthesis has been open but not closed. Return "CLOSE" if a parenthesis has not been opened but has been closed. |
| IsStrongPunctuation() | boolean | Returns true if the current boundary is ".", "?" or "!". Returns false otherwise. |
| NextLetterCapital() | string | In the following descriptions, the current boundary is surrounded by square brackets. Returns "CapitalAfterInitial" for any pattern like: W[.] Shakespeare Returns "CapitalAfterQuote" for any pattern like: blah di blah[.]" Hello or blah di blah[.] "Hello Returns "CapitalAfterDash" for any pattern like: blah di blah[.] - Hello Returns "true" for any other pattern like: "blah di blah[.] Hello Returns "false" otherwise. Note that there MUST be whitespace between the separator and the capital letter for it to be considered a capital letter. |
| NextLetters(integer n) | string | Returns the n exact characters immediately following the current boundary. |
| NextTokens(integer n) | string | Returns the n atomic tokens immediately following the current boundary. |
| PreviousLetters(integer n) | string | Returns the n exact characters immediately preceding the current boundary. |
| PreviousTokens(integer n) | string | Returns the n atomic tokens immediately preceding the current boundary. |
| Surroundings(integer n) | string | Examines the atomic tokens from n before the boundary to n after the boundary. For each token, if it is whitespace, adds " " to the result. If it is a separator, adds the original separator to the result. If it is a capitalised word, adds, "W", "Wo" or "Word", depending on whether the word is 1 letter, 2 letters, or more. Otherwise adds "word" to the result. |
The initial release of Talismane for French contained the following sentence detector feature file:
BoundaryString() IsStrongPunctuation() NextLetterCapital() InParentheses() Initials() PreviousLetters(IndexRange(1,4)) NextLetters(IndexRange(1,4)) PreviousTokens(IndexRange(1,3)) NextTokens(IndexRange(1,3)) Surroundings(IndexRange(1,3))
The Tokeniser
An atomic token is defined as a contiguous character string which is either a single separator, or contains no separators. The list of separators considered for this definition is as follows:
! " # $ % & ' ( ) * + , - . / : ; < = > ? @ [ \ ] ^ _ ` { | } ~ « » ‒ – — ―‛ “ ” „ ‟ ′ ″ ‴ ‹ › ‘ ’ * as well as the various whitespace characters: the space bar, the tab character, the newline, etc.
Thus, a text such as the following:
A-t-elle mangé de l'avoine ?
Will be separated into the following atomic tokens:
[A][-][t][-][elle][ ][mangé][ ][de][ ][l]['][avoine][ ][?]
In the Talismane suite, the tokeniser's role is to determine, for the interval between any two atomic tokens, whether it is separating or non-separating.
The default tokeniser provided with Talismane is a pattern-based tokeniser. This tokeniser assigns a default decision to each interval, unless the text within the interval matches a certain pattern. The default values are provided for each separator. If no value is provided, it is assumed the separator separates from both tokens before and after it. Otherwise, the following values can be provided:
Talismane's PatternTokeniser takes a configuration file in the specific format to list the default separator decisions and the patterns that can override these decisions.
First, the file contains a line for each default decision, followed by the separators to which it applies.
All other separators are assumed to separate tokens on both sides (IS_SEPARATOR)
Next, it should contain a list of patterns, using a syntax very similar to the Java pattern class, but somewhat modified - see the com.joliciel.talismane.tokeniser.patterns.TokenPattern class for details.
Optionally, each pattern can be preceded by a user-friendly name and a tab. Any line starting with a # is ignored.
For example, the following file could define patterns for French:
# Default decisions for separators IS_NOT_SEPARATOR - IS_SEPARATOR_AFTER ' IS_SEPARATOR_BEFORE # List of patterns ellipses \.\.\. Mr. \D+\.[ ,\)/\\] -t-elle .+-t-(elle|elles|en|il|ils|on|y) -elle (?!t\z).+-(ce|elle|elles|en|il|ils|je|la|le|les|leur|lui|moi|nous|on|toi|tu|vous|y) -t' .+-[mt]' celui-ci (celui|celle|ceux|celles)-(ci|là) ^celui-ci (?!celui\z|celle\z|ceux\z|celles\z).+-(ci|là) 1 000 \d+ \d+ 1,000 \d+,\d+ 1.000 \d+\.\d+
Specific feature functions available to the tokeniser
The tokeniser defines the following specific feature functions for any token:
| Function | Type | Description |
|---|---|---|
| AndRange(tokenAddress token*, boolean criterion, integer start, integer end) | boolean | Tests all tokens within a certain range for a certain criterion, and returns true only if all of them satisfy the criterion. If (start>end) will return null. Start or end are relative to the current token's index. If either refer to a postion outside of the token sequence, will test all valid tokens only. If no tokens are tested, will return null. If any test returns null, will return null. |
| BackwardLookup(tokenAddress token*, boolean criterion, integer offset*) | integer | Returns the offset of the first token to the left of this one
which matches a certain criterion, or null if no such token is found. If an initial offset is provided as a second argument (must be a negative integer), will only look to the left of this initial offset. Will always return a negative integer. |
| BackwardSearch(tokenAddress token*, boolean criterion, integer startOffset*, integer endOffset*) | tokenAddress | Returns the first token preceding this one which matches a certain criterion, or null if no such token is found. If a start offset is provided as a second argument (must be <=0), will start looking at this offset. If an end offset is provided as a third argument (must be <=0), will continue until the end offset and then stop. Note that, by default, it doesn't look at the current token (e.g. default start offset = -1) - to include the current token, set start offset = 0. Will always return a negative integer. |
| FirstWordInCompound(tokenAddress token*) | string | Returns the first word in a compound token. If not a compound token, returns null. |
| FirstWordInSentence(tokenAddress token*) | boolean | Returns true if this is the first word in the sentence. Will skip initial punctuation (e.g. quotation marks) or numbered lists, returning true for the first word following such constructs. |
| ForwardLookup(tokenAddress token*, boolean criterion, integer offset*) | integer | Returns the offset of the first token to the right of this one
which matches a certain criterion, or null if no such token is found. If an initial offset is provided as a second argument, will only look to the right of this initial offset. Will always return a positive integer. |
| ForwardSearch(tokenAddress token*, boolean criterion, integer startOffset*, integer endOffset*) | tokenAddress | Returns the first token following this one which matches a certain criterion, or null if no such token is found. If a start offset is provided as a second argument (must be >=0), will start looking at this offset. If an end offset is provided as a third argument (must be >=0), will continue until the end offset and then stop. Note that, by default, it doesn't look at the current token (e.g. default start offset = 1) - to include the current token, set start offset = 0. |
| HasClosedClassesOnly(tokenAddress token*) | boolean | Returns true if all of this tokens classes in the lexicon are closed, false otherwise. |
| LastWordInCompound(tokenAddress token*) | string | Retrieves the last word in a compound token. Returns null if token isn't compound. |
| LastWordInSentence(tokenAddress token*) | boolean | Returns true if this is the last word in the sentence (including punctuation). |
| LemmaForPosTag(tokenAddress token*) | string | The "best" lemma of a given token and postag (or set of postags), as supplied by the lexicon. |
| LexiconAllPosTags(tokenAddress token*) | string | Returns a comma-separated concatenated string of all lexicon pos-tags for this token. |
| LexiconPosTag(tokenAddress token*, string posTag) | boolean | Returns true if the token has a lexical entry for the PosTag provided. |
| LexiconPosTagForString(tokenAddress token*, string testString, string posTag) | boolean | Returns true if the string provided has a lexicon entry for the PosTag provided. |
| LexiconPosTags(tokenAddress token*) | string collection | Returns each of the postags of the current token, according to the lexicon, as a collection of strings. |
| LexiconPosTagsForString(tokenAddress token*, string testString) | string collection | Returns each of the postags of a given string, according to the lexicon, as a collection of strings. |
| NLetterPrefix(tokenAddress token*, integer n) | string | Retrieves the first N letters of the first entire word in the present token, as long as N < the length of the first entire word. |
| NLetterSuffix(tokenAddress token*, integer n) | string | Retrieves the last N letters of the last entire word in the current token, as long as N < the length of the last word. |
| Offset(tokenAddress token*, integer offset) | tokenAddress | Returns a token offset from the current token by a certain offset. Returns null if the offset goes outside the token sequence. |
| OrRange(tokenAddress token*, boolean criterion, integer start, integer end) | boolean | Tests all tokens within a certain range for a certain criterion,
and returns true if any one of them satisfies the criterion. If (start>end) will return null. Start or end are relative to the current token's index. If either refer to a postion outside of the token sequence, will test all valid tokens only. If no tokens are tested, will return null. If any test returns null, will return null. |
| PosTagSet() | string collection | A StringCollectionFeature returning all of the postags in the current postagset. |
| Regex(tokenAddress token*, string pattern) | boolean | Returns true if the token matches a given regular expression. |
| TokenIndex(tokenAddress token*) | integer | Returns the current token's index in the sentence. |
| UnknownWord(tokenAddress token*) | boolean | Returns true if the token is unknown in the lexicon. |
| Word(tokenAddress token*, string, string, ...) | boolean | Returns true if token word is any one of the words provided. Important: returns null (NOT false) if the the token word is not one of the words provided. |
| WordForm(tokenAddress token*) | string | Simply returns the current token's text. |
Note that all of the above features can be used by the pos-tagger as well.
The tokeniser defines certain features for patterns only.
For these features to work correctly, they should be fed the TokeniserPatterns() feature in place of the patternName. InsidePatternNgram should be fed TokeniserPatternsAndIndexes. See the example features below for details
| Function | Type | Description |
|---|---|---|
| TokeniserPatterns() | string collection | Returns a collection of pattern names for each pattern where current token is the FIRST TOKEN in a sequence of tokens matching the pattern. |
| TokeniserPatternsAndIndexes() | string collection | Returns a collection of pattern names and indexes for each pattern where current token is NOT the FIRST TOKEN in a sequence of tokens matching the pattern. The pattern name and index are separated by the character ¤ (as expected by the InnerPatternNgram feature). |
| PatternWordForm(string patternName) | string | Returns the actual text of the tokens matching the current pattern. |
| PatternIndexInSentence(string patternName) | int | Returns the index of the first token within the current pattern. |
| InsidePatternNgram(string patternNameAndIndex) | string | Gives the previous tokeniser decision for the atomic token just preceding the one indicated by a given index in the given pattern. Useful for ensuring that inner-pattern decisions are always respected (unless two patterns overlap in the same sequence), thus ensuring that multi-token compound words are either made compound as a whole, or not at all. The patternNameAndIndex should give a pattern name, followed by the character ¤, followed by the index to test. |
| PatternOffset(string patternName, integer offset) | tokenAddress | Returns a token
offset from the TokeniserPattern containing the present token. This allows us to find the word preceding a given compound candidate, or following a given compound candidate. Returns null if the offset goes outside the token sequence. |
The current release of Talismane for French contained the following pattern tokeniser features:
CurrentPattern TokeniserPatterns
CurrentPatternWordForm PatternWordForm(CurrentPattern)
PatternNgram ConcatNoNulls(TokeniserPatternsAndIndexes,InsidePatternNgram(TokeniserPatternsAndIndexes))
PrevTokenPosTag OnlyTrue(LexiconPosTag(PatternOffset(CurrentPattern, -1), PosTagSet))
NextTokenPosTag OnlyTrue(LexiconPosTag(PatternOffset(CurrentPattern, 1), PosTagSet))
PrevTokenUnknown OnlyTrue(UnknownWord(PatternOffset(CurrentPattern, -1)))
TokenP2Unknown|TokenP1WordForm ConcatNoNulls(CurrentPattern,ToStringNoNulls(OnlyTrue(UnknownWord(PatternOffset(CurrentPattern, -2)))), WordForm(PatternOffset(CurrentPattern, -1)))
NextTokenUnknown OnlyTrue(UnknownWord(PatternOffset(CurrentPattern, 1)))
TokenN1WordForm|TokenN2Unknown ConcatNoNulls(CurrentPattern,WordForm(PatternOffset(CurrentPattern, 1)), ToStringNoNulls(OnlyTrue(UnknownWord(PatternOffset(CurrentPattern, 2)))))
PrevTokenAllPosTags ConcatNoNulls(CurrentPattern,LexiconAllPosTags(PatternOffset(CurrentPattern, -1)))
TokenP2AllPosTags|TokenP1WordForm ConcatNoNulls(CurrentPattern,LexiconAllPosTags(PatternOffset(CurrentPattern, -2)), WordForm(PatternOffset(CurrentPattern, -1)))
TokenP2AllPosTags|TokenP1AllPosTags ConcatNoNulls(CurrentPattern,LexiconAllPosTags(PatternOffset(CurrentPattern, -2)), LexiconAllPosTags(PatternOffset(CurrentPattern, -1)))
TokenP2WordForm|TokenP1AllPosTags ConcatNoNulls(CurrentPattern,WordForm(PatternOffset(CurrentPattern, -2)), LexiconAllPosTags(PatternOffset(CurrentPattern, -1)))
NextTokenAllPosTags ConcatNoNulls(CurrentPattern,LexiconAllPosTags(PatternOffset(CurrentPattern, 1)))
TokenN1WordForm|TokenN2AllPosTags ConcatNoNulls(CurrentPattern,WordForm(PatternOffset(CurrentPattern, 1)), LexiconAllPosTags(PatternOffset(CurrentPattern, 2)))
TokenN1AllPosTags|TokenN2AllPosTags ConcatNoNulls(CurrentPattern,LexiconAllPosTags(PatternOffset(CurrentPattern, 1)), LexiconAllPosTags(PatternOffset(CurrentPattern, 2)))
TokenN1AllPosTags|TokenN2WordForm ConcatNoNulls(CurrentPattern,LexiconAllPosTags(PatternOffset(CurrentPattern, 1)), WordForm(PatternOffset(CurrentPattern, 2)))
PrevTokenSuffix NullIf(Not(UnknownWord(PatternOffset(CurrentPattern, -1))),ConcatNoNulls(CurrentPattern,NLetterSuffix(PatternOffset(CurrentPattern, -1),IndexRange(3,5))))
NextTokenSuffix NullIf(Not(UnknownWord(PatternOffset(CurrentPattern, 1))),ConcatNoNulls(CurrentPattern,NLetterSuffix(PatternOffset(CurrentPattern, 1),IndexRange(3,5))))
PrevTokenWordForm ConcatNoNulls(CurrentPattern,WordForm(PatternOffset(CurrentPattern, -1)))
TokenP2WordForm|TokenP1WordForm ConcatNoNulls(CurrentPattern,WordForm(PatternOffset(CurrentPattern, -2)), WordForm(PatternOffset(CurrentPattern, -1)))
NextTokenWordForm ConcatNoNulls(CurrentPattern,WordForm(PatternOffset(CurrentPattern, 1)))
TokenN1WordForm|TokenN2WordForm ConcatNoNulls(CurrentPattern,WordForm(PatternOffset(CurrentPattern, 1)), WordForm(PatternOffset(CurrentPattern, 2)))
FirstWord OnlyTrue(PatternIndexInSentence(CurrentPattern)==0)
FirstWordPerWordForm ConcatNoNulls(CurrentPattern,CurrentPatternWordForm(CurrentPattern),ToStringNoNulls(OnlyTrue(PatternIndexInSentence(CurrentPattern)==0)))
FirstWordOrAfterPunct PatternIndexInSentence(CurrentPattern)==0 | NullToFalse(LexiconPosTag(PatternOffset(CurrentPattern, -1),"PONCT"))
PrevTokenVerbLemma ConcatNoNulls(CurrentPattern,LemmaForPosTag(PatternOffset(CurrentPattern,-1),"V","VS","VIMP","VPP","VINF","VPR"))
PrevVerbLemma ConcatNoNulls(CurrentPattern,LemmaForPosTag(BackwardSearch(PatternOffset(CurrentPattern,-1),LexiconPosTag("V")|LexiconPosTag("VS")|LexiconPosTag("VIMP")|LexiconPosTag("VPP")|LexiconPosTag("VINF")|LexiconPosTag("VPR"), 0, -4),"V","VS","VIMP","VPP","VINF","VPR"))
The Pos-Tagger
The Pos-Tagger takes a token within a sequence of tokens representing the sentence, and assigns it a pos-tag. The tagset is fixed by the statistical model, which has to be trained to produce results in a particular tagset. Changing the tagset thus involves the following steps:
The pos-tagger allows for rules that bypass the statistical model. Writing a new set of rules is described here.
Specific feature functions available to the pos-tagger
Pos-tagger rules and features can include any functions defined by the tokeniser, except for those that are specific to patterns. In this case, functions will be applied to the tokens found by the tokeniser (whereas the tokeniser applied them to atomic tokens). In addition, the pos-tagger defines the following pos-tagger specific functions:
| Function | Type | Description |
|---|---|---|
| Ngram(integer n) | string | Retrieves and concatenates the tags assigned to the previous N tokens. Will only return results if the current index >= N-2 (to avoid multiple start tokens). This ensures that we don't repeat exactly the same information in 4-grams, trigrams, bigrams, etc... |
| History(integer offset) | posTaggedTokenAddress | Looks into the current history of analysis, and retrieves the pos-tagged token at position n with respect to the current token, where n is a negative integer. |
The following is a list of PosTaggedTokenFeatures - features that can only be applied to a pos-tagged token, and therefore can only be applied to tokens already pos-tagged in the current analysis (available via the History feature above). Note that these features can also be used by the parser, if an additional address function is added as a first parameter.
| Function | Type | Description |
|---|---|---|
| Category(posTaggedTokenAddress) | string | The main grammatical category of a given token as supplied by the lexicon. |
| ClosedClass(posTaggedTokenAddress) | boolean | Whether or not the pos-tag assigned to this token is a closed-class category. |
| Gender(posTaggedTokenAddress) | string | The grammatical gender of a given token as supplied by the lexicon. |
| Index(posTaggedTokenAddress) | integer | The index of a given token in the token sequence. |
| Lemma(posTaggedTokenAddress) | string | The "best" lemma of a given token as supplied by the lexicon. |
| LexicalForm(posTaggedTokenAddress) | string | The actual text of a given token. |
| Morphology(posTaggedTokenAddress) | string | The detailed morpho-syntaxic information of a given token as supplied by the lexicon. |
| Number(posTaggedTokenAddress) | string | The grammatical number of a given token as supplied by the lexicon. |
| Person(posTaggedTokenAddress) | string | The grammatical person of a given token as supplied by the lexicon. |
| PossessorNumber(posTaggedTokenAddress) | string | The grammatical number of the possessor of a given token as supplied by the lexicon. |
| PosTag(posTaggedTokenAddress) | string | The pos-tag assigned a given token. |
| PredicateHasFunction(posTaggedTokenAddress, string functionName) | boolean | For this pos-tagged token's main lexical entry, does the predicate have the function provided? |
| PredicateFunctionHasRealisation(posTaggedTokenAddress, string functionName, string realisationName) | boolean | For this pos-tagged token's main lexical entry, assuming the function name provided is in the list, does it have the realisation provided? If the function name provided is not in the list, returns null. |
| PredicateFunctionIsOptional(posTaggedTokenAddress, string functionName) | boolean | For this pos-tagged token's main lexical entry, assuming the function name provided is in the list, is it optional? If the function name provided is not in the list, returns null. |
| PredicateFunctionPosition(posTaggedTokenAddress, string functionName) | integer | For this pos-tagged token's main lexical entry, assuming the function name provided is in the list, what is its index? If the function name provided is not in the list, returns null. |
| PredicateHasMacro(posTaggedTokenAddress, string macroName) | boolean | For this pos-tagged token's main lexical entry, does the predicate have the macro provided? |
| Tense(posTaggedTokenAddress) | string | The tense of a given token as supplied by the lexicon. |
Although PosTag(History(n))=="x" and LexiconPosTag(Offset(n),"x") are similar, there is a fundamental difference between them:
- PosTag(History(n))=="x" examines the actual pos-tag assigned by the pos-tagger to a given token in the current analysis. As such, it can only be used with tokens preceding the current one, since they have already been assigned a pos-tag.
- LexiconPosTag(Offset(n),"x") takes a pos-tag as a parameter, and checks if a given token is listed in the lexicon as having that pos-tag. As such, it can be used for any token, including tokens following the current one which have not yet been analysed.
When a feature deals with a previous token to the current one, PosTag(History(n))=="x" is almost always preferable to LexiconPosTag(Offset(n),"x"). Thus, we would typically use PosTag(History(n))=="x" for all negative offsets, and LexiconPosTag for all offsets >= 0, as in: PosTag(History(-1))=="DET" & Word("deux","trois","quatre") & LexiconPosTag(Offset(1),"NC")
The current release of Talismane for French contained the following pos-tagger features:
LemmaOrWord(X) IfThenElse(IsNull(Lemma(X)),LexicalForm(X),Lemma(X))
WordFormRange WordForm(Offset(IndexRange(-1,1)))
Ngram(2)
Ngram(3)
NLetterPrefix(IndexRange(2,5))
NLetterSuffix(IndexRange(2,5))
LexiconPosTagF1 LexiconPosTags(Offset(1))
LexiconAllPosTags
LexiconAllPosTagsF1 LexiconAllPosTags(Offset(1))
WordFormF1LexiconAllPosTagsF2 ConcatNoNulls(WordForm(Offset(1)), LexiconAllPosTags(Offset(2)))
WordFormF1WordFormF2 ConcatNoNulls(WordForm(Offset(1)), WordForm(Offset(2)))
LemmaB1 LemmaOrWord(History(-1))
LemmaB1WordForm ConcatNoNulls(LemmaOrWord(History(-1)),WordForm())
LemmaB2LemmaB1 ConcatNoNulls(LemmaOrWord(History(-2)),LemmaOrWord(History(-1)))
PosTagB2LemmaB1 ConcatNoNulls(PosTag(History(-2)),LemmaOrWord(History(-1)))
LemmaB2PosTagB1 ConcatNoNulls(LemmaOrWord(History(-2)),PosTag(History(-1)))
LemmaB2LemmaB1WordForm ConcatNoNulls(LemmaOrWord(History(-2)),LemmaOrWord(History(-1)),WordForm())
PosTagB2LemmaB1WordForm ConcatNoNulls(PosTag(History(-2)),LemmaOrWord(History(-1)),WordForm())
LemmaB2PosTagB1WordForm ConcatNoNulls(LemmaOrWord(History(-2)),PosTag(History(-1)),WordForm())
PosTagB2PosTagB1WordForm ConcatNoNulls(PosTag(History(-2)),PosTag(History(-1)),WordForm())
UnknownB2PosTagB1 ConcatNoNulls(ToStringNoNulls(OnlyTrue(UnknownWord(History(-2)))),PosTag(History(-1)))
PosTagB2UnknownB1 ConcatNoNulls(PosTag(History(-2)),ToStringNoNulls(OnlyTrue(UnknownWord(History(-1)))))
OnlyTrue(LastWordInSentence())
OnlyTrue(FirstWordInSentence() & LexiconPosTag("CLS"))
IsMonthName() Word("janvier","février","mars","avril","mai","juin","juillet","août","septembre","octobre","novembre","décembre","jan.","jan","fév.","fév","avr.","avr","juil.","juil","juill.","juill","sept.","sept","oct.","oct","nov.","nov","déc.","déc")
IsDayOfMonth Word("31") & AndRange(NullToFalse(Word("31","au","[[au]]",",","et","à")), 0, ForwardLookup(IsMonthName())-1)
ContainsSpace OnlyTrue(Regex(".+ .+"))
ContainsPeriod OnlyTrue(Regex(".*[^.]\.[^.].*"))
EndsWithPeriod OnlyTrue(Regex("(.*[^.])\."))
ContainsHyphen OnlyTrue(Regex(".+\-.+"))
ContainsNumber OnlyTrue(Regex(".*\d.*"))
FirstLetterCapsSimple OnlyTrue(Regex("[A-Z].*"))
FirstLetterCaps OnlyTrue(Regex("[A-Z][^A-Z].*"))
FirstWordInCompoundOrWord IfThenElse(ContainsSpace(),FirstWordInCompound(),WordForm())
LastWordInCompound()
IsNumeric OnlyTrue(Regex("\d+(,\d+)?"))
AllCaps OnlyTrue(Regex("[A-Z '\-]+") & Regex(".*[A-Z][A-Z].*"))
UnknownWordB1 OnlyTrue(UnknownWord(Offset(-1)) & Not(ContainsSpace(Offset(-1))))
UnknownWordF0 OnlyTrue(UnknownWord() & Not(ContainsSpace()))
UnknownWordF1 OnlyTrue(UnknownWord(Offset(1)) & Not(ContainsSpace(Offset(1))))
NegativeAdverb() NullToFalse(Word("aucun","aucune","jamais","guère","ni","pas","personne","plus","point","que","qu'","rien"))
QueFollowingNeg Word("que","qu'") & OrRange(NegativeAdverb, BackwardLookup(Word("ne","n'")), -1)
LexiconPosTagCurrentWord LexiconPosTagsForString(IfThenElse(UnknownWord&NullToFalse(ContainsSpace),FirstWordInCompound,WordForm))
LeOrLaFollowedByUpperCase Word("Le","La","Les","L'") & FirstLetterCapsSimple(Offset(1))
The Parser
In shallow dependency parsing, a labelled dependency arc is drawn between each token in the sentence and at most one governor. Tokens without a governor are attached to an artificial "root" node. Circular dependencies are not permitted. Converting dependency parsing to a classification problem is done in Talismane via a shift-reduce algorithmas per [Nivre, 2008]. Thus, the parser is given a parse configuration consisting of three structures:
Given a particular parse configuration, the parser must select a transition from the set of allowable transitions, which will modify the parse configuration in a specific way, thus generating a new parse configuration. Typical transitions perform actions such as:
Depending on the transition scheme, transitions can also perform actions such as removing the top-most element in the stack or in the buffer. Transitions which generate dependencies are generally represented by n different transitions, one per allowable dependency label. Parsing may now be restated as a classification task as follows: given a parse configuration, which transition (selected from a closed pre-defined set) is the correct one to apply.
Parser features thus apply to parse configurations, and can draw upon any information included within the parse configuration. This includes information concerning the pos-tagged token in a specific position in the stack or buffer, information about the existing dependencies of this token, or information relating two tokens (e.g. top-of-stack and top-of-buffer) such as the distance between them.
Specific feature functions available to the parser
The following are the list of "address" functions which take a parse configuration and return a particular pos-tagged token:
| Function | Type | Description |
|---|---|---|
| Buffer(integer index) | address | Retrieves the nth item from the buffer. |
| Dep(address referenceToken, integer index) | address | Retrieves the nth dependent of the reference token. |
| Head(address referenceToken) | address | Retrieves the head (or governor) of the reference token. |
| Offset(address referenceToken, integer offset) | address | Retrieves the token offset from the current token by n (in the linear sentence),
where n can be negative (before the current token) or positive (after the current token). The "current token" is returned by the address function. |
| LDep(address referenceToken) | address | Retrieves the left-most left-hand dependent of the reference token. |
| RDep(address referenceToken) | address | Retrieves the right-most right-hand dependent of the reference token. |
| Seq(integer index) | address | Retrieves the nth pos-tagged token in the sequence of tokens. |
| Stack(integer index) | address | Retrieves the nth item from the stack. |
| ForwardSearch(address referenceToken, boolean criterion) | address | Looks at all pos-tagged tokens following the reference token in sequence, and returns the first one matching certain criteria. |
| BackwardSearch(address referenceToken, boolean criterion) | address | Looks at all pos-tagged tokens preceding the reference token in sequence (starting at the one closest to the reference token), and returns the first one matching certain criteria. |
The following are the list of feature functions which act directly on a pos-tagged token returned by an address function:
| Function | Type | Description |
|---|---|---|
| DependencyLabel(address) | string | The dependency label of a given token's governing dependency, where the token is referenced by address. |
In addition, all PosTaggedToken features from the pos-tagger above may be used by the parser, as long as an address is provided as the first parameter. The address will retrieve a pos-tagged token to apply the feature to.
The following additional functions allow comparison between two tokens or information about token dependents:
| Function | Type | Description |
|---|---|---|
| DependentCountIf(address referenceToken, boolean criterion) | integer | Returns the number of dependents already matching a certain criterion. |
| BetweenCountIf(address token1, address token2, boolean criterion) | integer | Returns the number of pos-tagged tokens between two pos-tagged tokens (and not including them) matching a certain criterion. |
| Distance(address token1, address token2) | integer | Returns the distance between the token referred to by addressFunction1 and the token referred to by addressFunction2, as an absolute value from 0 to n. |
The current "baseline" parser features for Talismane for French are the following:
# Functions for use below IfThenElseNull(X,Y) NullIf(Not(X),Y) IsVerb(X) PosTag(X)=="V" | PosTag(X)=="VS" | PosTag(X)=="VIMP" | PosTag(X)=="VPP" | PosTag(X)=="VINF" | PosTag(X)=="VPR" LemmaOrWord(X) IfThenElse(IsNull(Lemma(X)), LexicalForm(X), Lemma(X)) Lexicalised(X) IfThenElse(ClosedClass(X), LemmaOrWord(X), PosTag(X)) LexicalisedVerb(X) IfThenElse(ClosedClass(X) | IsVerb(X), LemmaOrWord(X), PosTag(X)) # Main features PosTagStack0 PosTag(Stack[0]) PosTagBuffer0 PosTag(Buffer[0]) LemmaStack0PosTagBuffer0 Concat(LemmaOrWord(Stack[0]),PosTag(Buffer[0])) PosTagStack0LemmaBuffer0 Concat(PosTag(Stack[0]),LemmaOrWord(Buffer[0])) LemmaStack0LemmaBuffer0 Concat(LemmaOrWord(Stack[0]),LemmaOrWord(Buffer[0])) PosTagBuffer1() PairGroup PosTag(Buffer[1]) PosTagBuffer12() PairGroup ConcatNoNulls(PosTag(Buffer[1]), PosTag(Buffer[2])) PosTagBuffer123() PairGroup ConcatNoNulls(PosTag(Buffer[1]), PosTag(Buffer[2]), PosTag(Buffer[3])) PosTagStack1() PairGroup PosTag(Stack[1]) PosTagBeforeStack() PairGroup PosTag(Offset(Stack[0],-1)) PosTagAfterStack() PairGroup PosTag(Offset(Stack[0],1)) PosTagBeforeBuffer() PairGroup PosTag(Offset(Buffer[0],-1)) PosTagAfterBuffer() PairGroup PosTag(Offset(Buffer[0],1)) DepLabelStack() PairGroup DependencyLabel(Stack[0]) DepLabelLDepStack() PairGroup DependencyLabel(LDep(Stack[0])) DepLabelRDepStack() PairGroup DependencyLabel(RDep(Stack[0])) DepLabelLDepBuffer() PairGroup DependencyLabel(LDep(Buffer[0])) LexicalFormStack0() PairGroup LexicalForm(Stack[0]) LexicalFormBuffer0() PairGroup LexicalForm(Buffer[0]) LexicalFormBuffer1() PairGroup LexicalForm(Buffer[1]) LexicalFormStackHead() PairGroup LexicalForm(Head(Stack[0])) LemmaStack0() PairGroup Lemma(Stack[0]) LemmaBuffer0() PairGroup LemmaOrWord(Buffer[0]) LemmaBuffer1() PairGroup LemmaOrWord(Buffer[1]) LemmaStackHead() PairGroup LemmaOrWord(Head(Stack[0])) GenderMatch() PairGroup Concat(Gender(Stack[0]),Gender(Buffer[0])) NumberMatch() PairGroup Concat(Number(Stack[0]),Number(Buffer[0])) TenseStack0() PairGroup Tense(Stack[0]) TenseBuffer0() PairGroup Tense(Buffer[0]) TenseBuffer1() PairGroup Tense(Buffer[1]) TenseStackHead() PairGroup Tense(Head(Stack[0])) TenseMatch() PairGroup NullIf(IsNull(Tense(Stack[0])) & IsNull(Tense(Buffer[0])), Concat(Tense(Stack[0]),Tense(Buffer[0]))) PersonMatch() PairGroup NullIf(IsNull(Person(Stack[0])) & IsNull(Person(Buffer[0])), Concat(Person(Stack[0]),Person(Buffer[0]))) MorphologyMatch() PairGroup Concat(Morphology(Stack[0]),Morphology(Buffer[0])) # Complete features above with info from the top-of-stack and top-of-buffer PosTagPair Concat(PosTag(Stack[0]),PosTag(Buffer[0])) LexicalisedPair IfThenElseNull(ClosedClass(Stack[0]) | ClosedClass(Buffer[0]), Concat(Lexicalised(Stack[0]),Lexicalised(Buffer[0]))) LexicalisedVerbPair IfThenElseNull(IsVerb(Stack[0]) | IsVerb(Buffer[0]), Concat(LexicalisedVerb(Stack[0]),LexicalisedVerb(Buffer[0]))) PairGroup_P ConcatNoNulls(PosTagPair(), PairGroup()) PairGroup_L ConcatNoNulls(LexicalisedPair(), PairGroup()) PairGroup_V ConcatNoNulls(LexicalisedVerbPair(), PairGroup())
Analysis mechanism
Beam search
Almost all of Talismane's modules make use of the beam search algorithm to reduce the search space. In a beam search, at each step of classification, the machine sorts the classifications by descending probability. Only the top n classifications are then considered for the next step, where n is called the beam width. For example, assume a beam width of 2. While pos-tagging, we determine that the first token is 50% likely to be a noun, 30% likely to be an adjective, and 20% likely to be a verb. Because of the beam width, we will only retain the 2 most likely classifications (noun, adjective) when analysing the second token. The pos-tag assigned to the first token affects the pos-tag probabilities for the second token (via n-gram and similar features). Note that we have excluded the possibility starting with a verb up front, even if it ended up being the correct choice in view of tokens downstream. Thus, the beam search is a method of maintaining linear complexity, at the cost of heavy pruning at each stage of analysis.
For a beam search to function, there are several requirements:
The first point above is dealt with in the probabilistic classifier section below.
The second and third points are straightforward when we compare sequential analyses, as in the case of a simple left-to-right pos-tagger. It is more subtle when we compare parser analyses, as they are not handling the tokens in a sequential order. We now have to decide whether to compare analyses by the number of transitions, the number of dependencies created, etc., and how to calculate a total score without necessarily favouring the shortest path to a solution. One option is discussed in [Sagae and Lavie, 2006].
Probabilistic classifier
As mentioned above, the beam search algorithm used by Talismane requires a probabilistic classifier, which can generate a probability distribution of classifications for each context to be classified.
Talismane has three probabilistic classifier implementations currently available:
- Maximum Entropy: also known as MaxEnt (see [Ratnaparkhi, 1998]), using the Apache OpenNLP Maxent implementation.
- Perceptrons: also using the Apache OpenNLP implementation.
- Linear SVM: using the LibLinear-Java adaptation of the original LibLinear implementation [see Ho and Lin, 2012].
In order to function, statistical probabilistic classifiers convert the training corpus into a series of events. Each event reduces a given linguistic context in the training corpus to a set of features (and feature results), and a correct classification for this context. Thus, if in the pos-tagger, our only two features are sfx3, the three-letter suffix of a token, and ngram2, the pos-tag of the previous token, we would reduce the second token in the sentence "Le/DET lait/NC a/V tourné/VPP" to the event ([sfx3:ait, ngram2:DET], class:NC) - and this is the full extent of the classifier's knowledge of this context. The linguist's role is to select features likely to be informative for the task at hand. More subtly, the linguist must try to define features as generically as possible while maintaining their information content, so that they will project well onto new contexts outside of the training corpus.
The statistical model generally assigns a weight to each feature/classification combination. Some features are found to be more informative for some classifications, while others are more informative for others. However, the a posteriori knowledge of weights assigned does not make it any easier to garner an understanding of the relative importance of features in the overall classification accuracy. First of all, we are typically dealing with tens of thousands of features, dozens of which act in combination on any linguistic context. Secondly, we could be dealing with numeric features (e.g. distance between two tokens), in which case the weight assigned to the feature interacts with its value in a given context to give the final result. Thus, the statistical model itself can be viewed as a black box for the linguist: it provides fairly accurate results, but looking inside it to try to gain a better understanding of the language is a fairly hopeless task.
Looking inside the black box
Still, Talismane does provide a way of reviewing the exact mathematics behind any specific decision made during analysis, through the argument includeDetails=true, which creates a file containing all of the mathematical details: the feature results returned for each context, the weight and value for each feature, and the final probability distribution. The command would look like:
java -Xmx1G -jar talismane-fr-version.jar command=analyse inFile=corpus.txt outFile=postag_corpus.txt encoding=UTF-8 includeDetails=true
Auto-evaluation
It is possible to evaluate the performance Talismane's pos-tagger and parser modules on any annotated data which uses the same tagset (and dependency labels for the parser). The following steps are typically involved:
- Analyse a new corpus
- Correct the analysis manually
- Evaluate the corrected corpus
- Review the errors
Auto-evaluation allows us to gauge Talismane's accuracy for corpora other than the training corpus, in this case the French Treebank. It also allows us to construct an evaluation corpus semi-automatically, and thus be able to measure improvement in Talismane's accuracy for a wide variety of corpora based on changes in training or analysis configuration.
To illustrate the auto-evaluation procedure, an example corpus (in French) will be used, taken from the discussion page of the wikipedia article on Organisme Génétiquement Modifié (genetically modified organisms). In this example, the discussion will be placed in a file called corpus.txt. We will discuss auto-evaluation for the pos-tagger module, but a very similar procedure can be used for the parser module.
Analysing a new corpus
First of all, we need to create the file corpus.txt containing the text to be evaluated. In our case, the top of the file will be:
Nouvelle page de discussion Pour plus de lisibilité sur cette page, les anciennes discussions ont été archivées. Pour relancer une discussion ancienne, il suffit de consulter les archives et de copier-coller le contenu souhaité dans la présente page. Question de définition Bonsoir. Afin de ne pas raconter n'importe quoi, l'insertion de gène d'une même espèce conduit-il à un OGM ? Exemple : transfert d'un gène d'une variété de blé résistant à un insecte à une autre variété de blé ? Si oui, cette précision manque dans la définition, car on a toujours l'impression d'avoir affaire à des chimères.--Manu (discuter) 29 avril 2008 à 22:53 (CEST)...
Next, we need to get Talismane to analyse this corpus automatically, assigning pos-tags to the tokens. The pos-tagged corpus will be stored in a file called pre_postag_corpus.txt, as follows:
java -Xmx1G -jar talismane-fr-version.jar command=analyse startModule=sentence endModule=postag inFile=corpus.txt outFile=pre_postag_corpus.txt encoding=UTF-8
Note that the auto-evaluation is currently performed on the pos-tags only, and not on the lemmas and additional morpho-syntaxic information provided by the glossary. The user may wish to correct the pos-tags only, in which case he can perform a Unix cut on the file to get rid of the additional columns as follows:
cut -f2,4 < pre_postag_corpus.txt > postag_corpus.txt
The file postag_corpus.txt should now look something like:
Nouvelle ADJ page NC de P discussion NC Pour P plus ADV de P lisibilité NC sur P .. ..
Correcting the analysis manually
Given the file postag_corpus.txt, we now need to check manually whether the sentence detection and tokenisation have found all the correct tokens, and whether correct pos-tag has been assigned to each token. Regarding French pos-tags, the user is referred to the morpho-syntaxic guide accompanying the French Treebank project. When correcting the pos-tag, the user has to be careful to choose a pos-tag from the pre-defined tagset, and to respect the tab characters within the file.
Evaluating the corrected corpus
We can now use Talismane to auto-evaluate its performance on the manually corrected postag_corpus.txt file, as follows:
java -Xmx1G -jar talismane-fr-version.jar command=evaluate module=postag inFile=postag_corpus.txt outDir=eval/ encoding=UTF-8 inputPatternFile=posTagCapture.txt
If the user has cut the file to keep only two columns, posTagCapture.txt would look like:
TOKEN\tPOSTAG
Otherwise, if the user has kept the original default pos-tagger output, posTagCapture.txt would look like:
.*\tTOKEN\t.*\tPOSTAG\t.*
The outDir parameter designates a path to the output directory, in this case the eval directory, in which the auto-evaluation files will be stored. These files will include:
- postag_corpus.fscores.csv: a confusion matrix listing the error counts, precision, recall and f-score by pos-tag.
- postag_corpus_sentences.csv: the full set of evaluated sentences, including the correct answer and the first n responses returned by the beam search.
Reviewing the errors
Two Perl scripts, available under a GPL license, are provided with the Talismane distribution in order to help extract useful information from the raw postag_corpus_sentences.csv file. These are:
- sentence2errors.pl
- Generate statistics
- Create a separate file per error type, containing a .csv file with the sentences for this error type only.
- csv2ods.pl
- Convert the csv files into xls files in order to color-code the errors.
These Perl scripts need to be copied into the eval directory, and run as follows:
cp /path/*.pl /path/eval/ cd /path/eval perl sentence2errors.pl < postag_corpus_sentences.csv
The new directories stat and corpus_csv are automatically created. The stat directory contains the various statistics files, while the corpus_csv directory contains the files with the specific sentences per error type.
The generated .csv files are named after their error label. This takes on the form PosTag1 - PosTAg2, where PosTag1 is the pos-tag that should have been assigned, and PosTag2 is the pos-tag that was actually assigned. For example, the file ADJ-ADV.csv contains all of the sentences where a token was classified as ADV, whereas the evaluation corpus claims it should have been an ADJ.
Inside the corpus_csv directory, we can transform the csv files into color-coded xls files, highlighting the errors. The color is red for errors concerning the current file's error label, and green for errors of another type.
A single file can be color-coded using the following command:
perl csv2ods.pl corpus_csv/PosTag1-PosTag2.csv
All of the files can be color-coded in one fell swoop using the following command:
find corpus_csv/ -iname "*.csv" -exec csv2ods.pl '{}' \;
Training a new statistical model
Information on how to write implementations of new training corpus readers or new lexicon readers is beyond the scope of the present user's manual. More details on the Java code and interfaces may be found in the project JavaDoc, to which you will find a reference on Assaf Urieli's home page in the CLLE-ERSS laboratory.
However, a user with a license to use the French Treebank corpus may wish to define new feature files and train a new model using the built-in reader for the French Treebank. This is done using the train command.
Generic training parameters
Some training parameters are shared by all of the various training modules. These are listed below.
| Parameter | Description |
|---|---|
| algorithm | The machine learning algorithm to use for training. Options are MaxEnt, LinearSVM and Perceptron. |
| cutoff | The number of times a feature must appear in the training corpus to be considered - default is 0 |
| sentenceCount | the maximum number of sentences to process from the training corpus - default is all sentences |
| crossValidationSize | the number of parts to use for a cross-validation. |
| includeIndex | if crossValidationSize>0, the index of the sentence to include, if we start counting at 0 and reset at zero after reaching the crossValidationSize. Typically used for evaluation only. |
| excludeIndex | if crossValidationSize>0, the index of the sentence to exclude, if we start counting at 0 and reset at zero after reaching the crossValidationSize. Typically used for training only. |
| externalResources | a path to a directory or file containing external resources referred to by the features. See External Resources below. |
Depending on the algorithm, different parameters can be included.
For MaxEnt, these are:
| Parameter | Description |
|---|---|
| iterations | The maximum number of training iterations to perform |
For LinearSVM, these are:
| Parameter | Description |
|---|---|
| linearSVMSolver | Available options are: L2R_LR (L2-regularized logistic regression - primal), L1R_LR (L1-regularized logistic regression), and L2R_LR_DUAL (L2-regularized logistic regression - dual). The default value is L2R_LR |
| linearSVMCost | The cost of constraint violation (typically referred to as "C" in SVM literature). Default value: 1.0. |
| linearSVMEpsilon | The stopping criterion. Default value: 0.01. |
For Perceptron, these are:
| Parameter | Description |
|---|---|
| iterations | The maximum number of training iterations to perform |
| perceptronAveraging | Use averaged weighting instead of standard (integer) weighting. |
| perceptronSkippedAveraging | See the Apache OpenNLP documentation for more details on skipped averaging. |
| perceptronTolerance | If training set accuracy change < tolerance, stop iterating. |
Training and evaluating a new Sentence Detector model
To train a new sentence detector model, the command would be something like:
java -Xmx4G -jar talismane-core-version.jar command=train module=sentenceDetector corpusReader=ftb treebankDir=data/treebank/training sentenceModel=data/models/sentenceDetector/sentenceModel1.zip iterations=200 cutoff=5 sentenceFeatures=features/sentenceDetector_fr_baseline.txt
The parameters are as follows:
| Parameter | Description |
|---|---|
| sentenceModel | a path to the file where the new statistical model should be stored - MUST be a zip file |
| sentenceFeatures | a path to the file containing the sentence detector feature descriptors |
| treebankDir | a directory containing the training subset of modified XML files from the French Treebank corpus (see note above) |
Training and evaluating a new Tokeniser model
To train a new tokeniser model, the command would be something like:
java -Xmx4G -jar talismane-core-version.jar command=train module=tokeniser tokeniserModel=data/models/tokeniser/ftbTokeniser1.zip tokeniserFeatures=features/tokeniser_fr_baseline.txt tokeniserPatterns=features/tokeniserPatterns_fr.txt iterations=100 cutoff=0 corpusReader=ftb treebankDir=data/treebank/training lexiconDir=data/lexiconsSpmrl
The parameters are as follows:
| Parameter | Description | Git Location | ||||
|---|---|---|---|---|---|---|
| tokeniserModel | a path to the file where the new statistical model should be stored - MUST be a zip file | |||||
| tokeniserFeatures | a path to the file containing the tokeniser feature descriptors | talismane_trainer_fr/features | ||||
| tokeniserPatterns | a path to the file containing the tokeniser patterns | talismane_trainer_fr/features | ||||
| treebankDir | a directory containing the training subset of modified XML files from the French Treebank corpus (see note above) | |||||
| lexiconDir | a path to the directory containing a serialised digitised version of any lexicons being used for training. | |||||
talismane_trainer_fr/resources| tokenFilters | a path to a file containing any token filters to apply to the token reader before training this tokeniser model. These will automatically be applied before analysing any text with this model. | talismane_trainer_fr/token_filters.txt | tokenSequenceFilters | a path to a file containing any token sequence filters to apply to the token reader before training this tokeniser model. These will automatically be applied before analysing any text with this model. | talismane_trainer_fr/token_sequence_filters.txt | |
Training and evaluating a new Pos-Tagger model
To train a new pos-tagger model, the command would be something like:
java -Xmx4G -jar talismane-core-version.jar command=train module=posTagger posTaggerModel=data/models/posTagger/ftbPosTagger_test1.zip posTaggerFeatures=features/posTagger_fr_baseline.txt iterations=100 corpusReader=ftb treebankDir=data/treebank/training lexiconDir=data/lexiconsSpmrl
The parameters are as follows:
| Parameter | Description | Git Location |
|---|---|---|
| posTaggerModel | a path to the file where the new statistical model should be stored - MUST be a zip file | |
| posTaggerFeatures | a path to the file containing the pos-tagger feature descriptors | talismane_trainer_fr/features |
| treebankDir | a directory containing the training subset of XML files from the French Treebank corpus. For the Pos-Tagger files can be the original FTB files. | |
| posTagSet | a path to the file containing the posTagSet to be used | talismane_trainer_fr/postags |
| posTagMap | a path to the file containing the mapping from FTB morpho-syntaxic labels to the selected tagset | talismane_trainer_fr/postags |
| lexiconDir | a path to the directory containing a serialised digitised version of any lexicons being used for training. | |
| tokenFilters | a path to a file containing any token filters to apply to the token reader before training this pos-tag model. These will only be applied if this pos-tag model is applied directly, without any tokeniser. | talismane_trainer_fr/token_filters.txt |
| tokenSequenceFilters | a path to a file containing any token sequence filters to apply to the token reader before training this pos-tag model. These will only be applied if this pos-tag model is applied directly, without any tokeniser. | talismane_trainer_fr/token_sequence_filters.txt |
Training and evaluating a new Parser model
To train a new parser model, the command would be something like:
java -Xmx4G -jar talismane-core-version.jar command=train module=parser parserModel=data/models/parser/parser1.zip parserFeatures=features/parser_fr_baseline.txt inFile=data/spmrl/spmrl.French.gold.conll lexiconDir=data/lexiconsSpmrl transitionSystem=ArcEager dependencyLabels=data/spmrl/spmrlDependencyLabels.txt algorithm=LinearSVM linearSVMEpsilon=0.01 linearSVMCost=0.25 cutoff=1 corpusReader=spmrl
The parameters are as follows:
| Parameter | Description | Git Location |
|---|---|---|
| parserModel | a path to the file where the new statistical model should be stored - MUST be a zip file | |
| parserFeatures | a path to the file containing the parser feature descriptors | talismane_trainer_fr/features |
| iterations | the number of training iterations to perform | |
| cutoff* | the number of times a feature must appear in the training corpus to be considered - default is 0 | |
| corpus | a training corpus file from the dependency treebank corpus created by [Candito et al, 2010] | |
| posTagSet | a path to the file containing the posTagSet to be used | talismane_trainer_fr/postags |
| lexiconDir | a path to the directory containing a serialised digitised version of any lexicons being used for training. | |
| tokenFilters | a path to a file containing any token filters to apply to the token reader before training this parser model. These will only be applied if this pos-tag model is applied directly, without any tokeniser. | talismane_trainer_fr/token_filters.txt |
| tokenSequenceFilters | a path to a file containing any token sequence filters to apply to the token reader before training this parser model. These will only be applied if this pos-tag model is applied directly, without any tokeniser. | talismane_trainer_fr/token_sequence_filters.txt |
| posTaggerPreprocessingFilters | a path to a file containing any token sequence filters to apply before training this parser model. These will typically add empty tokens where required. These will only be applied if this pos-tag model is applied directly, without any pos-tagger. | talismane_trainer_fr/posTagger_preprocessing_filters.txt |
Custom external resources
Talismane allows you to incorporate external resources in features. These external resources are assumed to be files which tie a set of keys to one or more classes, and optionally weights. For example, you may have a file which maps the set of keys [lemma, postag] to a single class [semanticGroup]. Or you may map the same set of keys [lemma, postag] to multiple [semanticGroup] classes, with different weights per class.
The default external resource file structure is as follows:
The default name will be the filename.
If a line starts with the string "Name: ", the default name will be replaced by this name.
If a line starts with the string "Multivalued: true", the resource will be considered multivalued with weights.
All lines starting with # are skipped.
Any other line will be broken up by tabs:
For multi-valued resources, the second-to-last tab is the class, the last tab is the weight.
For normal resoruces, the last tab is the class.
All previous tabs are considered to be key components.
The same set of key components can have multiple classes with different weights.
Thus, the following file is a legal external resource file:
Name: SemanticClass Multivalued: false NC orange fruit NC pomme fruit NC vélo véhicule NC voiture véhicule ADJ bleu couleur ADJ jaune couleur
A multivalued file might look like this:
Name: SemanticMultiClass Multivalued: true NC orange fruit 0.6 NC orange aliment 0.4 NC pomme fruit 0.7 NC pomme aliment 0.3 NC pain aliment 1.0
It is recommended to normalise all values so they are between 0.0 and 1.0
External resources are specified via the externalResources argument in the trainer mechanism.
They are automatically stored in the statistical model, so that they can be re-used during analysis.
Two features can be used to make use of external resources: ExternalResource(string name, string keyElement1, string keyElement2, ...) and MultivaluedExternalResource(string name, string keyElement1, string keyElement2, ...). Thus, we could add the following features to a feature file when training:
IsVerb(X) PosTag(X)=="V" | PosTag(X)=="VS" | PosTag(X)=="VIMP" | PosTag(X)=="VPP" | PosTag(X)=="VINF" | PosTag(X)=="VPR"
LemmaOrWord(X) IfThenElse(IsNull(Lemma(X)), LexicalForm(X), Lemma(X))
SemanticClass(X) ExternalResource("SemanticClass",IfThenElse(IsVerb(X),"V",PosTag(X)),LemmaOrWord(X))
LemmaStack0SemClassBuffer0 ConcatNoNulls(LemmaOrWord(Stack[0]),SemanticClass(Buffer[0]))
SemanticClassPair ConcatNoNulls(SemanticClass(Stack[0]),SemanticClass(Buffer[0]))
In the above example, we can remplace "SemanticClass" by "SemanticMultiClass", in which case the string being returned will be replaced by a string collection.
Performance monitoring
Talismane includes a built-in performance monitoring mechanism, via the optional performanceConfigFile argument.
If provided, the user can determine which packages or classes should be monitored for performance. A typical file would look like this:
talismane.monitoring.activated=true talismane.monitoring.default=false talismane.monitor.com.joliciel.talismane.lexicon=true talismane.monitor.com.joliciel.talismane.parser=true talismane.monitor.com.joliciel.talismane.parser.features=false talismane.monitor.com.joliciel.talismane.parser.features.BetweenCountIf=true
In this file, we tell Talismane to switch on monitoring, but not to start monitoring by default. Monitoring will only be applied to any classes in the com.joliciel.talismane.lexicon and com.joliciel.talismane.lexicon.parser packages and sub-packages, with the exception of the com.joliciel.talismane.parser.features sub-package, but switched on again for the feature com.joliciel.talismane.parser.features.BetweenCountIf.
The result is a CSV file given total performance per class, and performance when we removed any monitored sub-classes.
Feature testing
While designing feature set for specific purposes, you may want to test your features on an annotated corpus to see the results they provide. Talismane provides the possibility of doing this in process mode, by applying one of the pre-programmed options.
Pos-tagger feature testing
Pos-tagger feature testing is applied by choosing command=process and option=posTagFeatureTester, with module=postag. Currently, pos-tag feature testing needs to apply to a pre-defined set of words, indicated using the testWords option with a comma-separated list of words. The features to test are indicated by the posTaggerFeatures option. The test results are written to the directory indicated by the outDir option.
For example:
java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=process option=posTagFeatureTester module=postag inFile=data/spmrl/train.French.gold.conll posTaggerFeatures=data/features/targeted/test1.txt testWords=que;qu' outDir=data/features/targeted externalResources=data/features/targeted/externalResources suffix=_Test1
The above command will generate a file in the outDir directory, giving the feature results by feature name, feature result, and annotated corpus pos-tag.
Parser feature testing
Parser feature testing is applied by choosing command=process and option=parseFeatureTester with module=parser and predictTransitions=true. The features to test are indicated by the parserFeatures option. The test results are written to the directory indicated by the outDir option.
For example:
java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=process option=parseFeatureTester module=parser inFile=data/spmrl/test.French.gold.conll parserFeatures=data/features/parserTarget/test1.txt outDir=data/features/parserTarget/results/ predictTransitions=true suffix=_Test1
The above command will generate a file in the outDir directory, giving the feature results by feature name, feature result, and annotated corpus parsing transition.
Running Talismane is Server mode
It is possible to run Talismane as a server in a client/server application by using the mode=server option, in which case Talismane will listen on a port indicated by the port option (7272 by default). This can be used for analysis and processing. Note that in order to indicate to the Talismane server that it needs to process the text sent immediately (rather than waiting for a certain "block" of characters), the client needs to send three end-of-block characters (\f by default, can be changed using the endBlockCharCode option). If you are processing small blocks of text at a time, this can be much more efficient, since memory-greedy resources (e.g. lexicons and models) are preloaded at server start-up.
Launching Talismane as a server looks something like this:
java -Xmx1G -jar talismane-core-version.jar languagePack=frenchLanguagePack-version.zip command=analyse mode=server encoding=UTF-8 port=7171
A typical client that interacts with this server would look like this:
package com.joliciel.test.talismaneClient;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.Socket;
import java.nio.charset.Charset;
public class TalismaneClient {
public static void main(String[] args) throws IOException {
if (args.length != 2) {
System.err.println(
"Usage: java EchoClient ");
System.exit(1);
}
String hostName = args[0];
int portNumber = Integer.parseInt(args[1]);
// open socket to server
Socket socket = new Socket(hostName, portNumber);
OutputStreamWriter out = new OutputStreamWriter(socket.getOutputStream(), Charset.forName("UTF-8"));
BufferedReader in = new BufferedReader(
new InputStreamReader(socket.getInputStream(), Charset.forName("UTF-8")));
BufferedReader stdIn =
new BufferedReader(new InputStreamReader(System.in, "UTF-8"));
String fromServer;
String fromUser;
// Get next input from the user, ending with a blank line
String input = "\f";
while ((fromUser = stdIn.readLine()) != null) {
System.out.println("Client: " + fromUser);
if (fromUser.length()==0)
break;
input += fromUser + "\n";
}
// end input with three end-of-block characters to indicate the input is finished
input += "\f\f\f";
// Send user input to the server
out.write(input);
out.flush();
// Display output from server
while ((fromServer = in.readLine()) != null) {
System.out.println("Server: " + fromServer);
}
socket.close();
}
}
Note that server mode can use any of the analysis options available in normal mode. Thus, you can indicate the start and end modules, as well as various filter files (text filters, token filters), etc.
Acknowledgements
A special thanks to Jean-Philippe Fauconnier, who helped write the first version of this user manual.
References
End of document